
Amida – Fracking Upstream Data to Access Buried Sources

- Tell us about Amida. How did you get involved with data management, interoperability and security?
- There are many companies offering a variety of data services on the market. What is unique about Amida?
- One of the issues I know you’ve focused on speaking about is fractured data policies. Can you explain a bit about that and why it is a key component of data management and security?
- Amida offers a variety of different products and services. Can you briefly outline them?
- You’ve used the term ‘data fracking’ – can you discuss what that means and why it matters?
- Let's take a step back for a moment. What do you see as the most significant challenge to data security and management today?
Data is key to providing modern and complex problems and providing services in a timely fashion. However, data is often stored or accessed in ways that are single-use and are difficult to extract. Peter L. Levin, Co-founder and CEO of Amida, believes that by focusing on the upstream sources of data, data management, interoperability and exchange can be optimized.
Tell us about Amida. How did you get involved with data management, interoperability and security?
My most recent job was an appointee at the Department of Veterans Affairs and there I saw the problems they were having with health data interoperability. There were so many smart people and so much money being spent on downstream apps – machine learning tools and the like – for care management and/or for predictive analysis. Yet, at the end of the day, these projects were falling apart because we couldn’t get the right data to the right place at the right time. I’m an infrastructure guy, which means I’m always in the trenches, making sure the pipes are clean and the plumbing is working.
The way we position ourselves is that we focus on the upstream of resources that drive modern web apps. We aren’t really in the business of data analytics per se. What we believe, and what many of our customers believe as well, is that the challenges are upstream, at the data sources – where data models are often corroded or incomplete. Imagine that you have a Ferrari, but with no gas in it. When you go to the gas station, you don’t care from where the oil comes from – whether it’s from the tar sands of Canada or the desert sands of the Middle East – you just want to it work. It is the same as booking a flight or going to doctor or using the web – you don’t really care or have to understand how it works, it just does. So we focus on the infrastructure, data management part which is the hardest part of modern website services, that enables our customers focus on their value-add, and not have to worry about issues of data interoperability. We allow for their data to be usable and accessible no matter what their ultimate function is.
There are many companies offering a variety of data services on the market. What is unique about Amida?
Our staff is the most unique part of our company - from the board directors and senior advisors to the most junior member of the team. We really value transparency, candor, and encourage a work hard-play hard environment. It isn’t for everyone and certainly not everyone in Washington DC; government towns tend to have a different pace. If you are the kind of person that enjoys the intellectual challenge of working out a problem and then going to grab a beer – you’d do well at Amida. Furthermore, our staff is very interdisciplinary when solving problems. We have people from tech, of course, but also philosophy, education, and the humanities; this is key to helping to solve a myriad of challenges our clients face.
Another key point differentiating us is that although we are not ideological about open source, we do believe that when you are involved in public services – and public service – it is a key element. In the United States and abroad, we see that the public is often stuck using old, closed, proprietary systems and is often trapped by the providers of those services or systems because of financial or other considerations. In contrast, open source allows for the freedom to swap not just the software but also the service providers, allowing you to maximize your investment and get the best possible solution. Many companies try to lock in their customers with proprietary software – we don’t. Rather, we are confident that you’ll benefit from the skills, abilities and price point we offer, and we’ve seen that to be the case, as evidenced by our outstanding retention rate.
One of the issues I know you’ve focused on speaking about is fractured data policies. Can you explain a bit about that and why it is a key component of data management and security?
When data policies are scattered and disorganized, the challenge lies in the inability to implement them effectively. Having multiple policies within an organization becomes burdensome and drains valuable resources. Our solution involves consolidating these policies and providing a user-friendly implementation guide, ensuring everyone is aligned and equipped with a readily accessible reference point. The key is to establish comprehensive and practical data policies that can be easily utilized.
The fragmentation I’ve spoken about is with regards to the operational element of the data infrastructure. For example, very often a CTO (Chief Technology Officer) or CIO (Chief Information Officer) will wish he had some service, app, or functionality which requires knowing where the data is, how to get to it etc. And here is the rub – that isn’t always so simple.
So, then a ‘solution guy’ comes along and says, “no problem, I’ll just make another database.” But that is really just like continually administering an antibiotic – eventually you build up resistance. Instead of a clear, coherent and complete strategy – you try to put a bandage on the problem and effectively kick it down the road. The simple fix now only solves the pain point right now without consideration for future changes, upgrades, integrations and the like.
Amida offers a variety of different products and services. Can you briefly outline them?
We have a tool chest of open source components – adaptors really – that allow us to quickly come in, assess the problem (since many can’t accurately describe their problem), and map and audit the system. We can do this since we’re what you might call database and data model masters. Just like you don’t want to be the first patient that a new doctor is treating, our experience and past performance is indicative of our ability to understand the problem and apply the right tools to create a real solution.
The ‘products’ we provide are assembled from open source components to solve specific problems. Often, the data required for some type of functionality or solution is distributed in different systems that are unable, in their current form, speak to each other. Our job is to provide data interoperability and exchange using open source and customized adapters that connect all these assets that are upstream with the applications themselves.
For example, the Global Alzheimer’s Foundation needed a patient registry for matching patients with clinical trials. As you can imagine, it is quite a challenge to be able to make it easy for patients or caregivers of patients who have cognitive impairments to find out about the research going on and be able to identify what they can and should do next. We created an administration portal that can accept data from many clinical providers, and filter and manage the data, so that pharmaceutical companies can identify the right people to be involved in trials and tests.
The truth is, at the right level of abstraction, all of these problems are the same to us. These are data management, interoperability, and security issues.
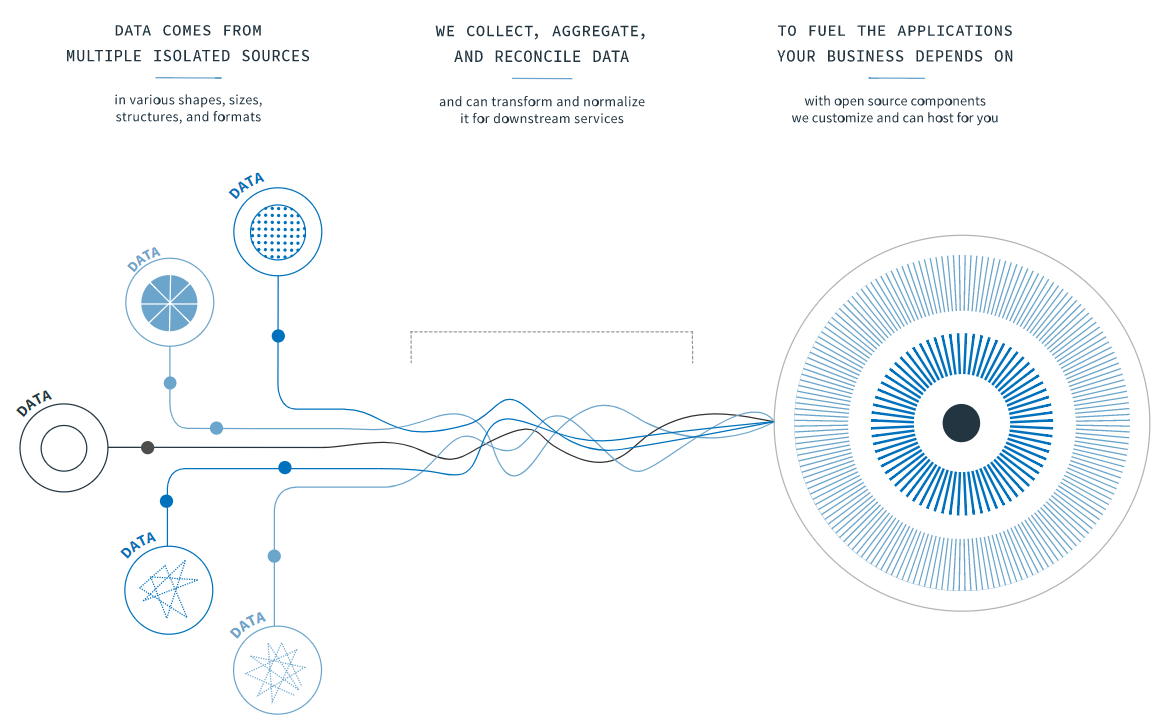
Amida works with healthcare organizations and government entities – how do you go about dealing with the massive amounts of data these bodies generate and manage?
As I just alluded to, the key here is the right level of abstraction. We begin every engagement by looking for the ‘cut set’ which means, at the lowest level of granularity, data sets and models that are very similar. Everyone has a name, address, birthday, health history, medicine, surgery, doctor, condition, immunizations, etc.
We just need to map the right data to the right place – much like a translator connects between two different systems of communication. Each side doesn’t need to learn the other language but rather use a translator to bridge the gap. Think of the problem through this prism. We just enable different types of data sources and platforms to ‘speak’ to one another, opening up communication channels between the different ‘sides.’
You’ve used the term ‘data fracking’ – can you discuss what that means and why it matters?
Fracking is going through extraordinary measures to extract resources that are stuck way underground. Sometimes what you need is on the surface so know where to start, and sometimes it is so deep and embedded you don’t even know where they are. If only you could gain access, you could do great things but you have no way to get to them since they are stuck in the rocks. The same thing goes for data and data sources that are trapped in ‘subterranean strata’ of paper and obsolete IT systems. We’ve been working on methods of extracting that incredible, sometimes life-saving data, to make it usable again for any number of systems or applications.
Let's take a step back for a moment. What do you see as the most significant challenge to data security and management today?
I would say that enterprise systems operators have two significant unknowns:
- They don’t always know what and where their data is. That is to say, they don’t have an accurate inventory of their assets and because of that they don’t know what their vulnerabilities are.
- They have an opaque view of their attack surface.
Think of it this way: the boundary between “outside” and “inside” has become very fuzzy and, unfortunately, very porous. That’s a consequence of the industry moving to the cloud, of course, but also the way we authenticate users, role-based access, configuration challenges, and dev-ops environments.
From my perspective, the benefits far outweigh the costs, but it makes the security situation more complex. What used to be a clear line of demarcation is, like I said, hard to define. On top of that, it is basically impossible to anticipate what the bad guy will do to you; remember, we have to keep track of every single thing that has been tried, have to patch what was successful, and have to try to anticipate what clever thing they’ll try next. The adversaries just have to find one way in, and even once they’re in you may not know, or they may wait to strike.
On the one hand, this is a really dire situation. On the other hand, it is why cybersecurity attracts some of the best minds in the field. From an academic/intellectual perspective, it is one of the most interesting problems we face in the digital community. The “surface” is multidimensional, and multiscalar. It doesn’t get more challenging than that.
Operationally and administratively, buy-in throughout the whole organization is critical – not just getting the Board of Directors to spend the resources on security. ‘Regular’ people need to buy into the idea of data management and security being important even if it isn’t or doesn’t seem related to their job function. At the end of the day, for those people as well, this is a critical issue that does affect them in one way or another.
About the Author
Eytan Morgenstern is a seasoned technology writer. He loves learning about new innovations, meeting the people behind them, and sharing their story.



Please, comment on how to improve this article. Your feedback matters!