
Intezer Analyzes Reused Code to Effectively Distinguish Between the Legitimate and the Malicious

- Please tell us a little bit about your background and current position at Intezer.
- What are today’s largest cybersecurity threats and what are the biggest challenges to identifying these threats before they attack?
- What is fileless code/malware?
- What technology have you developed to protect against these stealthy attacks?
- Please explain the use of the terminology “DNA” and “gene” and your “Code genome database” in the context of Intezer Analyze™.
- What are the advantages of being able to identify the source of the malicious code?
- So, you are constantly analyzing files and adding to the Genome database as new threats are detected?
- Are you then able to identify Zero Day Attacks?
- Isn't it possible that a threat actor not from North Korea could reuse code from WannaCry, knowing that the code analysis would point blame at North Korea?
- Can you show us an example of Intezer Analyze™’s DNA mapping in action?
- How does Intezer Analyze™ reduce false positives when detecting malware?
- Do you have any insight into the source of the ransomware attack on Atlanta back in March?
Dealing with hundreds of unknown files and many false-positives, performing memory analysis, and protecting against fileless malware represent some of the biggest challenges organizations are facing today. Intezer Analyze™ provides rapid malware detection and analysis by breaking down the code of every unknown file and comparing its “genes” to all previously seen code, both legitimate and malicious.
Please tell us a little bit about your background and current position at Intezer.
Before founding Intezer in 2015, I was head of the Israeli Defense Force’s CERT (Incident Response Team) where I dealt with nation-sponsored attacks on a daily basis. My duties included responding to these attacks, forensics, malware analysis and so on.
What are today’s largest cybersecurity threats and what are the biggest challenges to identifying these threats before they attack?
The biggest threats are those cyberattacks that don't generate any noise. Cyberattacks that are so stealthy that they do not present any anomaly or strange behavior, so they are able to avoid detection by most of the solutions available today. Included in these extremely stealthy attacks are fileless malware and in-memory attacks.
What is fileless code/malware?
Fileless attacks are quite complex. When someone sends you a file, you will see it on your desktop and your disk. However, there are ways for attackers to run pieces of code directly in memory so that you won't see any kind of file. This type of malicious “fileless” code is sometimes delivered via a “dropper” payload file that deletes itself once it runs this malicious code in memory.
What technology have you developed to protect against these stealthy attacks?
Intezer Analyze™ can both identify and analyze cyber threats, regardless of how a file may appear in relation to the current behavior of your network. Our approach is not to look at how a file behaves, which can be fooled or spoofed but to look at the origins of the file. So even if you have this very stealthy malware that doesn't generate any noise, we would still detect it by tracing the origins of its code.
Please explain the use of the terminology “DNA” and “gene” and your “Code genome database” in the context of Intezer Analyze™.
Our approach is actually very similar to real life DNA mapping. We can take any file or software that is running in your organization and dissect it into many little pieces of binary code we called “genes.” We then search and identify where we have seen every one of those genes in the past. For example, if you have a file that you know nothing about, we can alert you when we see a piece of code that was reused from known malware or known threat actors. So not only can we determine whether a file is good or bad but, in most cases, we can identify who is responsible for a certain cyberattack.
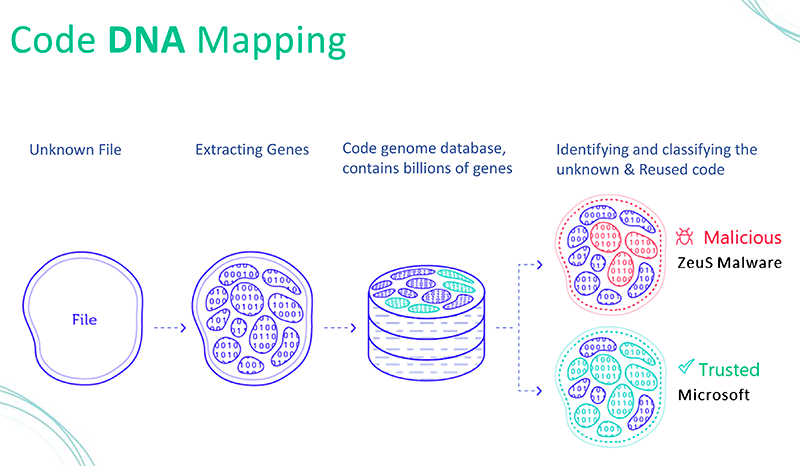
What are the advantages of being able to identify the source of the malicious code?
Two main reasons. One is that if you know where a piece of software originated, even if it doesn’t do anything special, but still it came from a certain threat actor, it is reasonable to conclude that this is a bad file.
Secondly, it can help you understand what you are dealing with. For example, if you know that you're dealing with an APT or an advanced threat actor, then the response itself would be significantly different than if you were dealing with just a common internet scam. Therefore, focusing on and accelerating the response is a very significant value you get from understanding the origins of code in the file.
So, you are constantly analyzing files and adding to the Genome database as new threats are detected?
Correct. The idea is to create this huge database of all the genes of all the pieces of code in the world of both legitimate and malicious software so that we can detect code reuse and code similarities in unknown or suspicious files. Just like Google must index more and more websites every day, we need to index more software and more malware every day, so our database is constantly growing.
You know, the amazing thing is that everybody reuses code. Even when Microsoft creates a new product, they reuse code. So, software really is evolutionary in both legitimate and malicious cases.
It’s this concept that makes our technology so effective - even a modest database that does not include all the threats or all the software in the world is of huge value.
Are you then able to identify Zero Day Attacks?
Absolutely. In fact, Zero Day Attacks are our sweet spot since these sophisticated threats are so stealthy that they manage to bypass today’s Next Generation solutions. Imagine you are a sophisticated threat actor who has spent about ten years developing your code for malware and cyber-attacks. You can’t really throw tens of years development into the trash and start from scratch every time.
A very good example is WannaCry, the most notorious ransomware ever created which last year infected millions of computers around the globe. We were the first company in the world to identify this threat as originating in North Korea. This is because we found pieces of code, DNA, inside WannaCry that we recognized as code that had only originated in previous North Korean malware. Detecting WannaCry though malicious reused code is our innovation here.
Isn't it possible that a threat actor not from North Korea could reuse code from WannaCry, knowing that the code analysis would point blame at North Korea?
That's a great question! To reuse the North Korean malware code, the other attacker would need the actual SOURCE CODE. It is practically impossible to reuse binary code, so they would need to hack into the North Korean government, steal their source code, and then recompile it with their modifications. So, this scenario is very, very unlikely.
Can you show us an example of Intezer Analyze™’s DNA mapping in action?
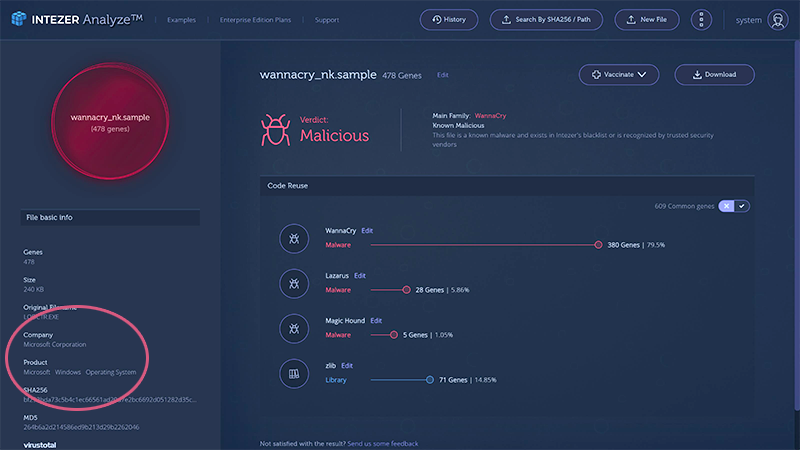
This instance involves a dubious file, which purports to be a Windows file. Immediately after I submitted the file for analysis and studied its 'DNA', it became apparent that we were able to isolate 462 'genes', or small segments of code.
Click here for an interactive demo.
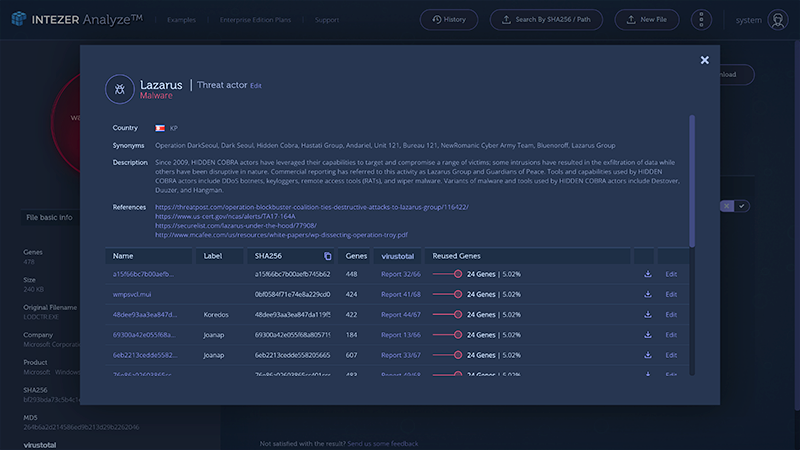
The right-hand side of the screen is where the magic happens, and the DNA mapping takes place. First, we do not see a single gene from Microsoft, meaning none of the code in this file was ever used in a Microsoft product. That tells us right away that this cannot be a Windows file. We also recognize that almost 80% of the code in this file has been seen in previous variants of WannaCry. Now the most interesting thing here is that almost 6% of the code, or 26 genes, were previously used in Lazarus, a North Korean threat actor who hacked Sony back in 2009. So, you see that even years after an attack, the original malicious code is still being used to create new malware.
How does Intezer Analyze™ reduce false positives when detecting malware?
As our genome database contains not only bad code but also legitimate code, we can identify whether a file is good or bad by analyzing code reuse and code similarities. For example, if you have a file from Microsoft which another solution or security system might deem suspicious because of its behavior, Intezer will recognize it as legitimate because 90% of its code has been seen in other Microsoft products. So, we reduce a lot of the false positives from other security systems because we just identified the DNA as that of a trusted vendor.
I always say that Skype is basically a virus resembling a spy tool as it records your keystrokes and has a camera. So, while Skype looks like it behaves bad, we know it is good as the code originated from and belongs to Microsoft. The best analogy is seeing someone in the street wearing a mask and carrying a gun, who looks and behaves dangerously. However, if you take his DNA and it matches a CIA agent, then you can understand that he is actually good.
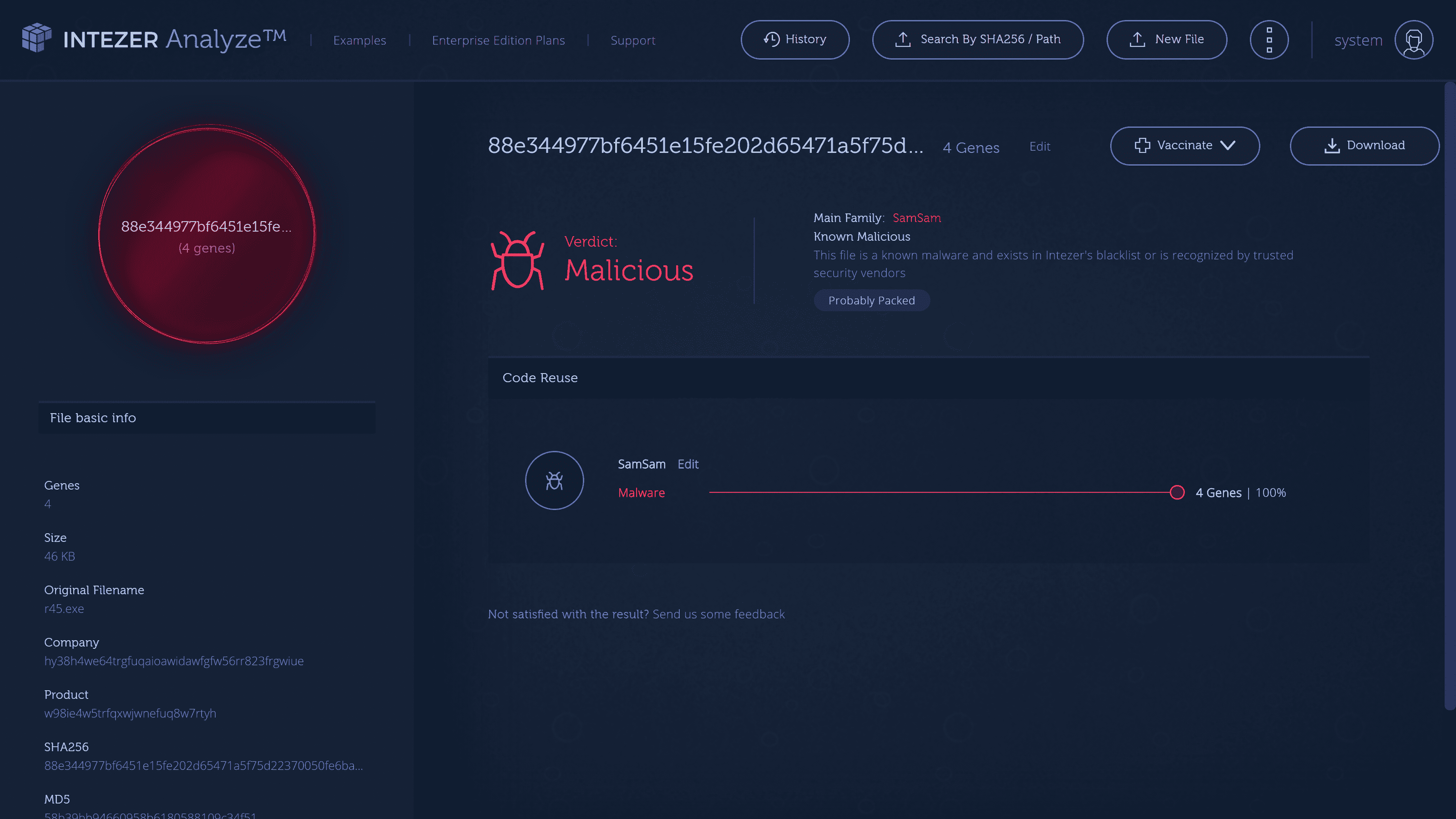
Do you have any insight into the source of the ransomware attack on Atlanta back in March?
Yes, in the case of the Atlanta cyberattack, they used ransomware called SamSam which shared code with other ransomware files. This screenshot shows how we recognized this file as malicious, identified the source and how our DNA mapping could have prevented this attack.
About the Author
Gail’s first PC was a TRS-80 which required a cassette tape to boot up. In the decades that followed, she created and developed websites, emails, and banners as the perfect way to combine her love for design, technology, and writing.



Please, comment on how to improve this article. Your feedback matters!