
Unauthorized Access: The Crisis in Online Privacy and Security- Free Chapter Included
Unauthorized Access: The Crisis in Online Privacy and Security is an outstanding piece of work by computer security and law experts Robert H. Sloan and Richard Warner. The book proposes specific solutions to public policy issues pertaining to online privacy and security. Requiring no technical or legal expertise, the book explains complicated concepts in clear, straightforward language. In this blog post, the 2 authors give vpnMentor readers a sneak preview to the 11th chapter of their book. Share
We wrote this book because we think that it's really important for people to understand both the technical, computer science issues behind electronic privacy and security and the legal and public policy issues. We felt that there were a lot of books that did a good job of opening up one or the other of those two black boxes, but nothing that was doing a really good job of opening up both black boxes. We think everybody needs to know something about both subjects, and that it is especially important to get technical folk up to speed on the legal and public policy questions, so that technical folk can take part in the public policy discussions and decisions.
A serious thing we learned in the course of writing the book is just how important social norms are in governing all our interactions, and, alas, how little study there has been about how to encourage the development of good new norms in areas of rapid change. That problem is exacerbated when one party to the norms is a really wealthy and powerful company. One of the amusing (at least to us) things we learned is that some of the traditions of how professors should cite sources haven't kept up with rapid change. For example, how should we cite: "This really blunt statement about their online tracking methods used to be on their website www.xyz.com, presumably to promote themselves to companies they hoped would use them to place advertisements. Today they say something really bland on their website. However, you can still see the original by using the Internet Wayback Machine."
Unauthorized Access: The Crisis in Online Privacy and Security is available for purchase on amazon. Below is the 11th chapter from the book.
Chapter 11 - Tracking, Contracting, and Behavioral Advertising
Introduction
As you enter a shopping mall, a guard pins a wireless tracking device on you. A real-time data feed allows stores to tailor their sales pitch to your path through the mall. (“You were just in Abercrombie and Fitch; we have better prices.”) The information is also stored for later analysis and distribution.
When pinning on the device, the guard hands you a piece of paper that states that by accepting the device, you agree to the printed terms. Among other things, you agree to wear the device and to permit the data collection. Entering a store requires wearing one or more additional tracking devices, which pick up signals from merchandise to track what you look at and for how long. Additional pieces of paper assert your assent. You return some devices when you leave a store, but retain others that monitor your activity in other stores. By the time you leave the mall, you are covered in tracking devices. You return all of them except for the virtually invisible microscopic devices attached to your credit and debit cards. They will track you during your next visit to any shopping mall. The papers presented to you assert your agreement.
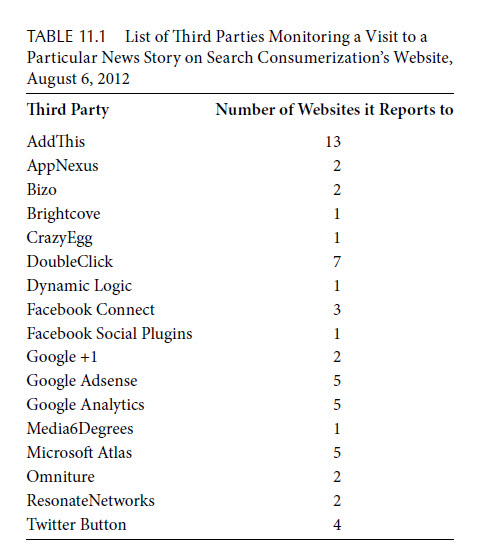
It is hard to imagine any of us tolerating this kind of tracking. We are, however, tracked in a very similar way on the Internet. In Table 11.1, we give a list of the third parties monitoring visits to Search Consumerization 1 and the number of websites to which each one reports.*
Some people try to prevent the tracking, but almost all acquiesce. Ignorance and a lack of obtrusive guards ease the acquiescence. Many are unaware of the various tracking technologies or are at least unclear about how they work; unlike our imagined mall guards, the technologies operate without altering our website experience (with the exception of the presentation of advertising targeted to our interests). Our compliance is a boon to business. Our data “have become a torrent flowing into every area of the global economy.”2 IBM estimates that the world now creates 2.5 quintillion bytes of data a day,3 and the prediction, according to a sponsored report by the research firm IDC, is that this will increase 44-fold by 2020.4
* For example, Resonate Networks reported back to two URLs, both http://ds.reson8.com/vendor.gif?v=CS&c=50047642d33884a4 and http://ds.reson8.com/pop.gif?v=CS&c=50047642d33884a
4&RCOUNT=18. The number of distinct websites that a particular third party reports back to may indicate the particular engineering design that that third party has chosen rather than the amount of tracking that it is doing. Still, it is quite impressive that AddThis reported back to 13 different URLs.
Until recently, handling extremely large data sets was infeasible, but advances in information processing have greatly increased companies’ ability to analyze “big data,” the term typically applied to the massive collections of information that once defeated our technological prowess. Big data promises big benefits. One recent study predicts that big data will save $200 billion annually in health care costs in the United States, increase retailers’ margins up to 60 percent, and create an annual consumer surplus of $600 billion.5 Even conservative estimates project considerable gains.
The downside is a loss of informational privacy— a massive loss of control over what others know about us. As we mentioned back in Chapter 1, with enough data, companies can determine where you work, how you spend your time, and with whom; as one big data expert put it, “With 87 percent certainty, I can tell you where you’ll be next Thursday at 5:35 p.m.”6 Various tributaries feed the torrent of data: website visits, mobile device apps, postings on social networking sites, credit card transactions, discount cards, retailers, visits to the pharmacist, public records, and so on. We consider more of the deluge in the next chapter. Here, we focus exclusively on behavioral advertising on websites.
We proceed as follows. First, we will say a little bit about the overall online advertising ecosystem. Next, we will take a close look at cookies, which are the technological equivalent of the wireless tracking devices from our introductory example. We conclude the chapter with a discussion of the legal devices equivalent to the contracts the guards handed out. Then, in the next chapter, we discuss what how we think things should change.
Behavioral Advertising and the Online Advertising Ecosystem
(Online) behavioral advertising is “the tracking of consumers’ online activities in order to deliver tailored advertising.”7 Tracking, tailoring, and delivery occur through a complex ecosystem of interacting entities. The behavioral advertising ecosystem consists of a large number of different types of interacting businesses. We offer a simplified model consisting of just five roles: profilers, advertising agencies, advertising exchanges, websites
displaying the advertisements, and the businesses that purchase the advertising.8 A single business entity may, of course, perform more than one role.
Profilers create focused descriptions that segment buyers into groups in order to predict their willingness to buy specific types of products and services.* A good example is eXelate, which, according to its website, is “the world’s largest digital data engine powering 60 billion privacy-compliant data transactions for 200 media companies every month.” eXelate has agreements with hundreds of websites that allow it to collect information about age, sex, ethnicity, marital status, profession, Internet search information, and sites visited. It combines these data with data from offline sources. eXelate explains,
We are capturing billions of deep granular data points…We analyze [these]…and roll them into specific Targeting Segments…These categorizations include Demographic data…, consumer Interest data gathered from specific site activity…(such as parenting and auto enthusiast sites), and deep purchase Intent data culled from relevant activity on top transactional sites. We further segment and sub-segment this data into relevant buckets that in many cases drill down to the product and keyword level.9
Practitioners of behavioral advertising sometimes insist that the information does not identify particular individuals. Based on their own claims, this is simply not true. The profiler TARGUSinfo, for example, boasts on its corporate website that “with our authoritative data and proprietary linking logic, no other company can match our ability to accurately identify businesses and consumers in real time—helping you target and recognize your best prospects, even at the moment of live interaction.”10 The data include “names, addresses, landline phone numbers, mobile phone numbers, email addresses, IP addresses and predictive attributes.”11
The purpose of the profiles is to target display advertising. A business may create its own display advertising, or it may outsource that to another agency. Advertising exchanges deliver display advertisements to websites that display them. When a buyer visits a website, the exchange retargets advertisements by combining a buyer’s profile with information about the buyer’s current website activity. The exchange then conducts an auction in which businesses bid for the opportunity to present their targeted advertisements. The whole process takes milliseconds. As one commentator aptly sums up the situation, “Advertisers bid against each other in real time for the ability to direct a message at a single Web surfer.”1
* The creation of profiles distinguishes behavioral advertising from contextual advertising. In contextual advertising, an automated system selects and displays advertisements based on the website content displayed to the user. Google’s keyword and AdSense programs are examples. Contextual advertising does not raise the intense privacy concerns that behavioral advertising does.
The amount of information processed is immense. Right Media Exchange, for example, processes nine billion advertising purchases daily.13 The goal is to tailor advertisements as closely as possible to the interests of the buyer receiving them. Datran Media, for example, promises “to identify who is visiting your Website, who is being exposed to your advertisers’ campaigns, and who is responding to specific ads. Real-time reports paint an accurate picture of whom [sic] your audience really is and who is responding to your communications—at the household level!”14
Next we turn to the question of how this is done: What is the technology that allows a Datran Media, a Google, a Facebook, or an Internet service provider (ISP) to know what you are doing online, and precisely what do they know?
How Websites Gain Information About You: Straightforward Methods
Advertisers and others who want to compile information about web surfers need one key thing: a way to identify specific users. Visiting a website reveals the electronic address (IP address) of the visiting computer, but the goal of tracking technology is to go beyond that by labeling individual users with unique tags. The tags make it possible to recognize multiple visits as all coming from the same user. This is analogous to what people who study wild birds do: They temporarily capture a bird and put a small metal or plastic band with a unique number on it, so that they know when they see the same bird in the future. On the Internet, there are several ways this can be done.
You Identify Yourself Using a Login ID We start with the obvious. If you create a user ID with a website and log in
using that ID, then you are identified. For instance, if you go to Amazon’s website and buy copies of Moby Dick and The Great Gatsby, then Amazon will know your Amazon login ID, your e-mail address, your name, the information for the credit card you use to pay Amazon, your shipping address, and that you have purchased the books Moby Dick and The Great Gatsby. Furthermore, at least from a technological point of view, it is essentially free for Amazon to store that information forever and to add to it any future purchases you make.
The same holds for any online shopping website where you make a purchase. You have to give them your name, address, and credit card information so that they can send you what you bought. You might be able to avoid creating a permanent user ID, and you might even go to the trouble of getting a special e-mail address used for just such purchases; even so, your shipping address connects your purchases together and, in practice, most consumers will just create a login ID and give their e-mail address or perhaps one of their three or four e-mail addresses.
Moreover, all websites where you create a login name that you reuse know whatever information you provide them. It can be difficult to avoid reusing a login name. In many important cases, such as Facebook or Gmail (or Yahoo Mail or Microsoft’s Hotmail or Outlook.com), you must log in with a unique ID that you use all the time, because that is the essence of how the service works. Many, many more sites either require you or strongly encourage you to log in. For instance, at the time of this writing, one must log in to see anything beyond the front page at the New York Times website. Furthermore, once you log in to a website, the owners of that site know which of its pages you are requesting. So Amazon can see that user FSFitzgerald17 has been looking at a lot of 1920s literature pages, and Google Maps can see that FSFitzgerald17 has been searching for maps of West Egg, New York.
A unique login ID is the very best sort of information, because it definitively picks out one individual. All the following ways that websites attempt to tag you are basically attempts to do as well as if you used a login ID.
Websites Know Your IP Number
Recall from Chapter 2 that all information on the Internet is sent using IP, the Internet protocol, and that every computer on the Internet is assigned a unique address, called an IP number. Every packet (chunk of data) sent in each direction of every conversation between a web browser and a website includes both the “to” and “from” IP addresses, so all the websites you visit know your IP address.
We should emphasize that “every” really means “every” in this case. It is true that all the major web browsers currently provide some form of privacy mode (called InPrivate browsing in Internet Explorer, Private Browsing in both Firefox and Safari, and Incognito mode in Google Chrome). However, all that mode does is to stop recording certain information on your own computer; the browser must still send your IP number.
Similarly, when you send encrypted information, such as a credit card number, you nevertheless provide your unencrypted IP number. Encryption protocols such as secure sockets layer (SSL) or transport layer security (TLS) encrypt the contents of packets, but not the headers. Your IP number is the address to which the web page you see is delivered, so it cannot be hidden or encrypted. An analogy would be that you could get a traditional mail message that was in a special tamper-resistant envelope or that was encrypted, but your address would still need to be on the outside of the envelope so that it could be delivered to you.
Today, the typical US household gets Internet service that does not provide a permanent IP address, but rather one that the ISP is allowed to change from time to time. In practice, a typical household will keep the same IP number for between a few weeks and several months. It is generally public information which ISPs control which IP numbers, and the ISPs typically assign them to consumers in geographic blocks, so, in fact, from your IP number alone, a website might be able to determine, say, that you are located somewhere in the greater Chicago region and get DSL (digital subscriber line) broadband Internet service from AT&T. If you have been browsing the web and seen information on pages that seemed tailored to your part of the country, this is one way in which that may have been done. Of course, for the typical household that buys a connection to the Internet from one ISP, the IP address identifies only the household, not individual users.
Cookies: A Deeper Dive into the Technology
We discussed cookies or, more precisely, HTTP cookies back in Chapter 5, where we said that the cookies themselves play the role of bands used to tag and later identify birds. Now is a good time to explain more about how the mechanics of the web and cookies work. At a very low level, as we said in Chapter 2, the entire Internet, including the web, works by machines sending packets according to the IP. For the web in particular, the hypertext transfer protocol (HTTP) is used to govern the communications between your computer’s web browser and a web server. (Sometimes a more secure variant, HTTPS, is used. HTTPS is basically HTTP plus encrypting the contents of the packets.)
To request a web page, you either type in its web address—formally, its uniform resource locator (URL)—into the address bar of your web browser, or you click on a link, which automatically enters the URL into the address bar of your web browser. Consider the URL http://www.cnn.com/TECH, which currently is the web address of the Technology section of CNN. As we show in Figure 11.1, a URL can be broken into three parts. First comes the protocol, which is almost always http or https for the web, followed by a separator consisting of a colon and two slashes.

Next comes the host name, also called the domain name, which is the name of the computer hosting the website, in this case, www.cnn.com. Recall that that name is simply a more human-friendly version of the host computer’s IP number (157.166.255.18 for www.cnn.com). The third part, called the path, starts with a slash and tells which page from the host computer you want. The shortest possible path is just the single slash, which gives you the “main” page (and your web browser will understand that you want the “main” page if you omit the path completely).
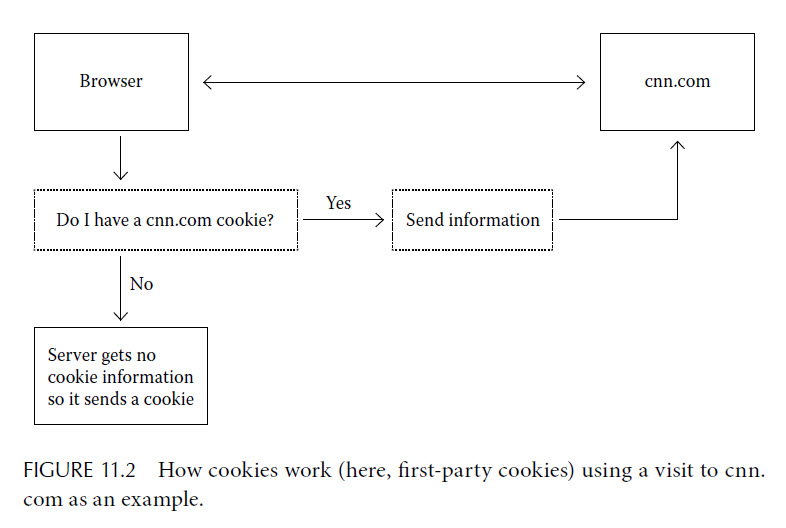
Now HTTP specifies that your computer begin its conversation with the www.cnn.com server by sending it the keyword GET, the path from the URL, and some parameters. Cookies are part of HTTP. Recall from Chapter 5 that HTPP specifies that a web server responding to your request can send your browser a cookie, which is a short text file, and that your browser is to send back that same text file every time it communicates with that same web server in the future. Thus, if you visit www.cnn.com without also sending a www.cnn.com cookie that was stored on your machine back to www.cnn.com, then www.cnn.com knows that this is your first visit to the site or that you have erased cookies since your last visit. We illustrate how cookies work in Figure 11.2.
Cookies can only be left by a website that is displaying information in your browser. However, the question of exactly who is displaying information in your web browser is more involved than it may first seem. When you visit a website, such as www.cnn.com, that address is what appears in your web browser’s address bar and the owner of that name is
serving you much of the content you are seeing. Precisely what happens in response to your HTTP GET response is that a page of HTML (the format in which web pages are written; it stands for hypertext markup language) is sent back to you. That page contains both some of the final content that is to be displayed and directions to download more content automatically without any further direct action on the user’s part. Typically, all images would be part of the additional content. Also, all material coming from third parties, such as advertisements, is part of that additional material.
At the moment we are writing these words, loading http://www.cnn.com/TECH/ also loads third-party material from Disqus, Double Click, Dynamic Logic, Facebook Connect, Insight Express, Dynamic Logic, and Revenue Science. CNN also loads various images relating to the news stories and some that appear to be advertisements being served by CNN itself, which presumably sold these ads.
Any cookies you get from the host you visited (CNN in our example) are called first-party cookies. Most or all of the benefits consumers get from cookies come from first-party cookies. Websites use them to remember various things, such as the contents of your shopping cart, what version of something you prefer to see, what you were doing at your last visit, your login information, etc.
A typical web user who never erases cookies might have many thousands of cookies on his computer. A 2010 Wall Street Journal investigation found that many of the most popular sites on the Internet were each causing anywhere from a couple dozen to well over a hundred cookies to be stored by users’ computers. How does it happen that some websites cause dozens of cookies to be deposited on your computer? A small part of the answer is that multiple cookies can be a convenience to a website. While each cookie can hold up to a few thousand characters, it may be more convenient to use one to remember what language you like things displayed in and another to remember some other aspect of your preferences. So www.cnn.com might deposit as many as 15 cnn.com cookies on your computer
rather than just 1.
However, the main reason that some websites leave you with a large number of cookies is that they are leaving third-party cookies.15 When you visit many websites, some of the content you see is being displayed by advertisers. A news site, in addition to its own material, may display various ads being served by any number of advertising companies and networks, such as DoubleClick (a subsidiary of Google), as well as by other companies advertising themselves, such as Facebook or CNet. Those websites can also leave cookies on your computer, and they are referred to as third-party cookies. We illustrate this process in Figure 11.3.
The main use of third-party cookies is to allow an advertising network to track you across various sites that you visit, presumably to tailor the advertising material that they show you to your browsing history. Of course, they can only track you across sites that they have a presence on, but the largest online advertising networks, such as DoubleClick, have a very wide presence. It is quite common for major websites to allow multiple trackers to gather information from their website. One evening early in 2011, we looked at half a dozen major news websites and found that each had between two and nine tracking networks tracking users at its site.
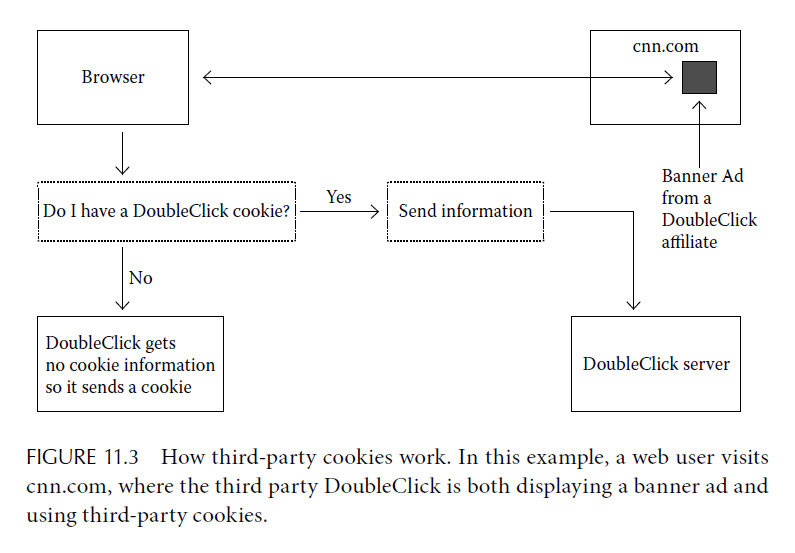
Almost all had Facebook connect, which allows Facebook users to “like” something on a page—and allows Facebook to know where one of its members has been surfing. A majority also had Omniture, a web analytics network. Straight ad-serving networks advertising on the news websites included Google AdSense, DoubleClick (owned by Google), MSN Ads (owned by Microsoft), and Tacoda.
In the past several years, a new kind of cookie has come into play: Flash cookies. A great majority of both Windows and Mac computers have Adobe’s Flash Player installed, and Flash can display all sorts of interesting animations. It turns out that Flash also gives web pages the ability to store information, called locally shared objects (LSOs) that can be used in the same way as traditional HTTP cookies and are referred to as Flash cookies. LSOs raise the same privacy issues as cookies, but users have less control over LSOs than they do over cookies. The major web browsers
all give users the option of not accepting cookies and of deleting specific cookies. Finding LSOs requires digging into obscure settings or using special-purpose add-ons to your web browser.
One use of LSOs is to defeat attempts to delete cookies. Many sophisticated users of the web have at least heard of cookies and may delete their cookies every so often. Some users may even have set their web browsers to reject third-party cookies. (A number of websites do not work properly if you reject all cookies, and a few don’t work properly if you merely reject third-party cookies, so not so many people do this.) Companies will use LSOs to duplicate the information in a conventional cookie and will check regularly to see if the user has deleted the regular cookie; if so, they will use the LSO to recreate that cookie.
The details of cookies will likely continue to evolve. For instance, Microsoft’s Silverlight is a competitor to Adobe’s Flash, and there may be similar issues of Silverlight cookies to those with Flash cookies if Silverlight becomes widely enough used. The overall language of the web is gradually being updated to HTML 5 (from earlier versions of HTML), and it too will introduce new issues concerning persistent storage of information on users’ computers that could be used for tracking.
Making a “Signature” out of Browser, OS, Fonts Installed, etc.
In theory, cookies may not even be necessary, because your web browser may already be sending enough information to websites to identify you uniquely. The HTTP protocol sends a great deal of information whose purpose is to allow websites to customize the layout of the information they send to your computer. Thus, you send your web browser, your operating system, your current screen resolution, the set of all fonts you have installed, and other such information. Furthermore, each piece of information is detailed. That is, your web request does not merely say, “This is coming from Firefox on a Mac,” or even, “This is coming from Firefox 15 on a Mac running Mac OS 10.6,” but rather, “This is coming from Firefox 15.0.1 on a Mac running Mac OS 10.6.8.” It has been calculated that the total set of information may indeed uniquely identify a computer.16
Other Ways of Getting Your Online Information
In the remainder of this book, we are going to concentrate on tracking web users using third-party cookies and using the information gathered by doing that to target advertising. That issue is extremely contentious at the time of this writing, and it vividly illustrates the problems that arise when society has no shared conception of what uses of information are role appropriate. However, we would be remiss if we did not briefly discuss some other electronic methods that advertisers and other interested businesses can use to obtain detailed information about you and your habits; by the time you are reading these words, one of these may be the most contentious issue of the day.
For starters, we should mention smartphones. Smartphone penetration in the United States is a hairsbreadth below 50 percent as we write these words and will surely have passed 50 percent by the time you are reading them. Smartphones are outstanding devices for tracking their owners.
Most of us have them on our persons almost all our waking hours, and recent studies claim that over two-thirds of us have them within reach of our beds when we sleep! Every iPhone and every Android and Windows 7 smartphone has a unique ID number, and those ID numbers are in principle accessible to every app running on those phones. Moreover, smartphones know where they are located. They all have GPS’s that give quite a precise location, and even if the GPS isn’t working, a smartphone can usually get a reasonably close approximation of its location from triangulating the cellular telephone signals it is receiving or from maps that link the visible WiFi networks to geographic location. This geographic information too is, in principle, available to every app running on your smartphone.
Yet another way that advertisers and others might learn about you is from your ISP or your cell phone carrier. Recall our discussions of deep packet inspection back in Chapter 8. Unless it is forbidden by law or by norm, then there is no reason why your ISP cannot read the information you are sending via Internet and sell parts of it to interested advertisers.
What is Wrong with Behavioral Advertising?
Now that we have discussed the technical means used for “pinning wireless tracking devices on us as we walk through the mall,” let us move on and next discuss something that may seem obvious: Why does tracking make so many people uneasy? What’s wrong with it? The basic problem is that businesses deprive buyers of choice about how businesses will process their information.
Lack of Choice for Buyers
Advertising is personalized. Information processing is not. It does not vary to conform to the privacy preferences of individual buyers. Efficient information processing requires standardized, automated routines using a great deal of computing power and advanced statistical techniques to analyze vast collections of complex mixtures of data from a variety of different online and offline sources. Marketing objectives—not buyers’ privacy preferences—drive the collection, analysis, and use of vast amounts of diverse types of information. As the CEO of the advertising exchange
Rocket Fuel notes, the company’s “technology drives results for advertisers by automatically leveraging massive amounts of internal and third party external data and serving only the best impressions in the context of each advertiser’s unique marketing objectives” (emphasis added).17
One important reason sellers do not tailor their information processing to buyers’ individual privacy preferences is that they do not need to. The vast majority of buyers acquiesce in information processing practices, thereby guaranteeing sellers significant advertising revenues. This means a seller can easily afford to ignore the relatively few buyers who refuse to do business with it unless it adjusts its information processing practices. But even so, shouldn’t we expect some sellers to break the mold to win business by catering to privacy preferences? That expectation would be disappointed. Sellers do not break the mold—not if they rely on advertising as a significant source of revenue.* Participation in the advertising ecosystem gives a seller a competitive edge over nonparticipants by making it a more attractive advertising platform. To compete, other sellers must also participate and, to gain an edge, they may need to adopt even more surveillance-intensive practices than their competitors.18
* Not all sellers do. Dropbox, for example, relies very successfully on user fees to generate revenue.
Our concern is with those sellers that rely primarily on advertising revenue.
Acquiescence via Contract
We do not resist our lack of choice; rather, we routinely acquiesce to information processing that feeds our information into the advertising ecosystem. As far as the law is concerned, we consent to the processing in legally
binding contracts: The terms of use agreements and privacy policies are accessible via hyperlinks. These are the online equivalents of the pieces of paper the guards and stores presented in our opening metaphor.
When we suggest to nonlawyers that a brief visit to a website creates a contractual relationship, their response is often, “That’s not just wrong. That’s bizarre.” Their reaction makes good sense. No one would suggest that you enter a contract with the New York Times when you scan the headlines as you stand in line at Starbucks, or with a bookstore when you leaf through a book, even if you read several pages. So how can it be right to say you enter a contract when, for example, you visit the news site CNN.com for a 2-minute glance at the latest headlines? How can our website visits, even our quick and casual ones, be enough to form a binding contract? The answer lies in two key differences between the offline and online cases. The first difference is that, on the web, businesses can easily collect
vast amounts of information about you from a simple website visit. For the moment, neither the New York Times nor the bookstore can collect information about you as you stand in line or browse through a book. The bookstore may collect information about you if you are using a loyalty card, but that requires your physically handing the cashier your loyalty card.
The second difference is that websites typically offer free products and services that would simply not be available offline, at least not for free. To take two quite different examples, first consider news websites. CNN, Fox News, BBC News, and so on all offer free, frequently updated, highquality, multimedia news coverage. Next think of the host of websites that are the home of some particular piece of software that you can freely download and then use on your computer. A very small sample of these includes Audacity, which offers an easy to use audio editor and recorder;
FlightGear, which offers a flight simulator; FreeMind, which offers a mind mapping tool; and Red Notebook, which offers a well thought of digital diary-writing application. All of these websites potentially collect information, since all of them make some use of third-party cookies. This is true even for sites like Audacity. Audacity is a not-for-profit open-source operation, and the audio editor itself collects no information when you run it on your computer.
However, Audacity’s website’s privacy page says, “…we show advertisements from Google’s AdSense program. See our ‘How Does Audacity Raise Money?’ page for the reasons,” and goes on to say “this includes ‘interest-based’ advertising, which utilizes cookies to try to determine users’ areas of interest (for example, audio editing), to show advertisements of likelier interest.” In other words, Audacity’s website uses online behavioral advertising to raise some revenue to support their non-profit activity.
The information provided to the owners of websites generates advertising revenue that offsets the cost of providing the good or service, so there is an exchange of information for a product or service. Such exchanges are characteristic of contractual relations. The exchange is like any traditional exchange of value—with two differences: First, the value provided is information, which will be used for advertising purposes. Second, usually the user doesn’t know that he or she agreed to anything.
Billions of such pay-with-data transactions occur daily. Pay-with-data transactions occur whenever someone visits a website to obtain a product or service, either for free or for a fee, and allows the use of his or her information for advertising or other commercial purposes, such as market analysis or sale to third parties. For convenience, let us call the visitors buyers and the website owners sellers—even when the exchange does not include a monetary fee.
Fixing What Is Broken
Pay-with-data exchanges are an instance of no-negotiation, one-size-fitsall contracts. The legal literature refers to this as standard-form contracting. This practice first flourished in the nineteenth century shortly after the rise of mass produced, standardized products, and—in the non-Internet world—it has by and large served as a fair and efficient way to allocate the risks and benefits between buyers and sellers of commercial goods and services such as hair dryers, toasters, microwaves, washing machines, home repairs, auto servicing, and many others.* We contract constantly; whenever we buy a cup of coffee, a book, a pair of pants, or a car, we are entering into a contract. Pay-with-data exchanges are also an instance of this practice, but a malfunctioning one that leads to unacceptable invasions of informational privacy.
* We by no means deny that sellers have sometimes exploited standard form contracts to impose unfair terms on buyers; auto leases in the 1970s and 1980s are one example.
So why not fix what is broken? Privacy advocates often criticize online standard-form contracting for its failure to provide meaningful choice, a conclusion with which we agree. But then the advocates often assume that contracting should go in the trash bin of useless tools. Contracting is just broken, not useless. We need to fix the tool that is, outside the digital context, a pervasive feature of our lives. We can use this familiar tool to protect our privacy in the online behavioral advertising context by making standard-form contracting work as well online as it does for tangible goods and services off the Internet. To do so, we need to understand what makes contracting work well in the non-Internet world. Our answer appeals to value optimal coordination norms that limit what contracts can say. There are well established, time-tested (and litigation-tested) appropriate norms for nondigital products and services, but norms are largely lacking in the digital realm.
Mention of “contractual norms” may suggest negotiation norms, like “Do not deceive the other party.” Our concern, however, is not with negotiation, and, as we will argue, the beauty of standard-form contracts is that there is no negotiation. Instead, we are concerned with contractual norms—the norms that apply to the content of the standard-form contract itself. Such norms answer the question, “Should this type of contract contain a particular type of term?” For example, the contracts governing the sale of refrigerators typically make sellers liable for defects in the motor but buyers liable for wear and tear on the shelves and doors. This allocation of risk reflects the best loss-avoider norm we discussed in Chapter 6.* The sellers’ expertise and economies of scale make them the best loss avoider for motor defects, but buyers are the best loss avoiders when it comes to doors and shelves because they can avoid damage simply by avoiding unreasonable use. As we will explain later, the best loss-avoider norm makes it appropriate to assign risks in those ways in refrigerator contracts.
The Second-Order Contractual Norm
To understand precisely what it is that is broken with current pay-withdata exchanges, we need to delve more deeply into the subject of norms governing contracts. Up to this point in this book, we have been considering only ordinary norms, such as the best loss-avoider norm, which are norms about something more or less concrete. In the case of contracts, we will also need to consider a second-order norm: a norm that itself refers to norms.
* The norm is that, other things being equal, the party who can most cost effectively prevent a loss should bear that loss.
Next we formulate the second-order norm, explain how it arises, and then show that it ensures that buyers give free and informed consent to acceptable contractual terms. The second-order norm is the term-compatibility norm: Buyers demand contractual terms compatible with relevant value optimal norms. We discover violations of the term-compatibility norm by detecting incompatibility with other norms. Those norms—the first-order norms— include the informational, product-risk, and service-risk norms discussed in earlier chapters.
To see how things work when the term-compatibility norm is in place, think back to the example in Chapter 6 of typical consumer Barbara, who discovered that her water heater no longer works. To continue the example here, imagine that Barbara does what many would do: She immediately orders a new water heater by phone and pays with a credit card. After the workers finish the installation, they hand her an envelope as they leave.The contract from the manufacturer of the water heater is inside. Barbara does not bother to open the envelope; she just puts it in a drawer along with her other unread contracts for consumer goods.
Her behavior is entirely rational. She is not an expert on either water heaters or contracts, and she would be unable to evaluate the contract adequately even if she did read it, since she would not fully grasp the significance of much of the legalese. But Barbara has no need to read the contract.
Given the term-compatibility norm, her consent is both informed and free without even looking at the contract.
The argument for this claim is essentially the one we gave in Chapter 4. All that is required for her consent to be informed is that she knows that the terms in the contract implement value optimal trade-offs. The definition of value optimal ensures that Barbara knows that the trade-offs, whatever they are, are justified by her values—and more: She not only knows they are justified, but she also knows that there are no alternatives that are better justified, which means that she knows that, given her values, she cannot get a better trade-off than the one the contract gives her.
Her consent is free because the standard-form contract is precisely the means she wants for her free pursuit of a variety of important goals.
In Chapter 4, we used the Cayman Islands vacation example to make the point. You cannot afford to realize your dream of vacationing in the Cayman Islands until you discover an “all inclusive” deal for airfare, hotel, and food. When you are on the islands, you have to eat the food that comes with the deal. Your budget leaves you no choice. Our point was that this constrained choice is part of an overall—freely chosen—plan. Eating the food is a means to realize your vacation dream freely and is, in that sense, something you freely choose to do.
The same point holds for Barbara. She wants to replace her water heater and get on with the important goals in her day and her life. She does not know enough about water heaters or contracts to read and assess various possible contractual arrangements, and it is unlikely that she would have the time to do so even if she did know enough. (Even many law school contracts professors rarely read such contracts.) The standard-form contract is the perfect solution. It gives Barbara a prepackaged deal that she knows is as good as she can get, given her values. Just like you in the Cayman Islands example, the constrained choice of the take-it-or-leave-it contract is the key means to pursuing her goals freely. It does not matter that Barbara agreed to unexamined terms when she bought the water
heater with her credit card and can’t back out later. Backing out is the last thing she wants to do.*
This is how things work when the term-compatibility norm is in place. Adherence to the norm ensures that contracts contain terms compatible with relevant first-order, value optimal norms, which ensures that standard- form contracts are freedom-enhancing agreements through which we give our free and informed consent.
To see exactly how standard form contracts accomplish this feat, there is one question left to answer: What does it mean for terms in a contract to be compatible with first-order norms?
Compatibility
One way to be compatible with first-order norms is simply to adhere to those norms. The “refrigerator motor, door, and shelves” example we used earlier illustrates the point. The contract makes the refrigerator seller liable for defects in the motor and the buyer liable for damage to the door and shelves, and, as we noted, this is exactly what the best loss-avoider norm requires.
* In addition, if Barbara is a sophisticated consumer, she also may know that contracts like her water heater contract have been litigated and are somewhat regulated, so she can’t be getting too bad a deal. It is unlikely that the terms violate standards articulated in cases and statutes.
Now there is a problem, one many have pointed out when we have presented our view of contracts. People object that our view is implausible because contracts routinely contain terms that are clearly inconsistent with relevant norms. So how can the norm be that contracts contain norm compatible terms? It takes some time to explain our answer, but doing so is essential to understanding how the contracting behavior we engage day in and day out actually works. Our answer is that we do not equate compatibility with straightforward adherence to norms. Norm-inconsistent terms cans still be norm-compatible terms, as we will now explain.
Norm-inconsistent terms are still compatible when they do not completely overturn the norm-implemented trade-off but just fine-tune it. The fitness norm is a good example.* Under the norm, sellers bear the risk of selling an unfit product, and buyers bear the risks associated with using a fit product. Standard-form contracts typically shift the risk of selling an unfit product onto the buyer by relieving the seller of any liability for an unfit product.† This shift merely fine-tunes the fitness norm’s risk allocation.
To see why, consider that, in a sufficiently competitive market, the penalty for producing more than the occasional unfit product is lost profits, so profit-motive-driven sellers will offer fit products—for the most part. No production process is perfect, so there will be some unfit products on the market. But these will be relatively rare. In this context, the effect of disclaiming the fitness norm is to place the relatively small remaining risk of using an unfit product on the buyer.
This may seem bad for risk-averse buyers and buyers facing unusually high risks who want more protection, but they can easily protect themselves by purchasing insurance or extended warranties, both of which are typically readily available at fairly reasonable prices. On the other hand, consider what happens when sellers do promise that a product is fit in the contract. Sellers will most likely raise prices to cover the additional legal liability, and this is bad for low-risk buyers who have little or no need of the additional protection. Those buyers pay for the protection they do not need, thereby subsidizing protection for risk-averse and high-risk buyers.
Disclaiming the fitness warranty avoids the subsidy. In this way, the disclaimer fine-tunes the initial risk allocation of the fitness norm by shifting some risk back onto buyers. Our view is that this fine-tuning is a value optimal adjustment of a value optimal norm.
* The fitness norm, which we discussed in Chapter 6, states that products should be fit for the ordinary
purpose for which they are used.
† Legally speaking, the contract disclaims the warranty of merchantability, which is a legal implementation
of the fitness norm.
This is why we define “terms compatible with value optimal norms” in a way that makes the various disclaimers count as compatible. Thus, a term in a standard-form contract is compatible with a first-order norm if it either is adhering to that norm or is an adequately justified fine-tuning of the risk allocations that norm implements.
Are We Right?
Why should anybody think the fundamental norm governing standard form contracts is the second-order, term-compatibility norm? Our answer: the term-compatibility norm is a consequence of the existence of first order norms. Using our by now familiar two-step argument, we show that it exists in an ideal market, and then we argue that it will exist in any real market that sufficiently closely approximates the ideal.
Once again, we temporarily assume perfect competition, this time in all mass markets in which standardized products or services are sold with standard-form contracts. As usual, since the definition of perfect competition requires similar goods and services, we should, strictly speaking, consider a wide variety of different markets, but we ignore this issue because, essentially, the same argument would apply to each of them. As we are using the notion of perfect competition, we must specify the type of relevant knowledge appropriate to each application. For buyers, we assume that buyers know all the terms in all sellers’ contracts and, for each term, know whether or not it is compatible with all relevant value optimal norms. We will also make assumptions about what sellers know, but we
will specify those later.
We also add a second ideal condition in addition to the perfect competition condition: contractual norm completeness.* Contractual norm completeness is the requirement that, for every possible contractual term, there is at least one value optimal, first-order norm with which that term is compatible or incompatible. In reality, as we have already seen, first-order norms may fail to be value optimal, or relevant norms may not exist at all. In addition, we assume that compatibility with norms is an all-or-nothing matter: A contractual term is either entirely compatible or entirely incompatible. In the real world, compatibility is often a matter of degree.
* This is a special case of the general notion of norm completeness we introduced in Chapter 4 and used in Chapter 5 in our discussion of privacy.
How the Norm Arises in Ideal Markets
To see how the term-compatibility norm arises, suppose a seller includes an incompatible term in a contract. We will show that sellers will replace incompatible terms with terms compatible with value optimal, first-order norms. Then all contracts will contain only compatible terms, and the result will be that “buyers demand terms compatible with value optimal norms” will be the norm, a behavioral regularity that exists in part because buyers think they ought to conform. We divide the argument into the part primarily about buyers and the part primarily about sellers.
Buyers: Perfect information guarantees that whenever a contract contains a term incompatible with a value optimal norm, all buyers realize that it does, and buyers also realize that the norm it conflicts with is value optimal. Such terms conflict with buyers’ values, and buyers will prefer to buy from sellers offering terms compatible with value optimal norms. Perfect information ensures that they know which sellers offer compatible terms. Given zero transaction costs, they can costlessly switch to such sellers, so they will do so—provided such sellers exist, which they will in a world with perfect competition.
Sellers: The argument that norm-compatible sellers will exist begins with further specification of the perfect knowledge condition: First, sellers know that buyers prefer to buy from sellers offering norm-compatible terms. Second, sellers know that buyers know, for each term in a contract, whether it is norm compatible. Since in our ideal world there are no barriers to entry or exit, sellers can costlessly alter their contracts (and, if necessary, their products and services) to offer terms compatible with all relevant value optimal norms. Profit-motive-driven sellers will do so since buyers will not otherwise buy from them.
The result is that “buyers demand terms compatible with value optimal norms” is a behavioral regularity. It exists in part because buyers think they ought to conform; they think they ought to because buying from norm-compatible sellers is what their values require. In this hypothetical ideal market, the term-compatibility norm is indeed a norm, but it is not a coordination norm. The argument is the same one we made about the best practices software norm in Chapter 7. In the ideal market, each buyer conforms solely because of his or her own values, independently of the behavior of everyone else. In both cases, in real markets the need for unified buyer demand in a mass market causes the norm that arises to be a coordination norm.
Real Markets: How the Coordination Norm Arises
Real markets only approximate our ideal conditions. If real markets approximate perfect competition and contractual norm completeness closely enough, the term-compatibility norm will emerge as a coordination norm. The argument repeats the argument in the ideal market case— with adjustments for reality.
We begin by adjusting for real contracts. In our hypothetical ideal world, contractual norm completeness guaranteed that every contractual term was either compatible or incompatible with at least one value optimal norm. So, in ideal markets, if we went through contracts and deleted every term that was either compatible or incompatible with a value optimal norm, we would have nothing left. If we try this in real markets, we may end up with some terms that are neither compatible nor incompatible. As we noted earlier, applicable norms may not be value optimal, or we may
just not have any relevant norms at all. The fewer applicable value optimal norms there are, the more terms will remain in the contracts. Even if contracts contain a lot of terms for which there are no applicable value optimal norms, buyers won’t go without goods and services they need.
They will still be willing to pay for—“demand” in our special sense of the term—the goods and services governed by such contracts. This means the result will be the opposite of what we want: not “buyers demand normcompatible terms” but rather “buyers do not demand norm-compatible terms.” We need enough value optimal norms to avoid this result.
We assume that we have them. We assume that the markets we are considering approximate contractual norm completeness sufficiently closely that we have enough value optimal norms. This assumption is legitimate, since our goal is only to show that if real markets sufficiently approximate perfect competition, then the norm will arise.* As we did in the ideal market case, we divide the rest of the argument into a “buyer” part and a “seller” part.
Buyers
When we discussed ideal markets, the perfect information assumption guaranteed that every buyer could spot the incompatible terms in any and every contract. How can we approximate this condition in real markets?
As we have emphasized, very few buyers in real markets read standardform contracts, and most would not understand them if they did.
* This point about the “if, then” nature of our argument comes up a few more times in what follows. In this particular case, it is worth noting that many markets do fairly closely approximate contractual norm completeness. Sellers have used standard-form contracts for over a century, and it is reasonable to think that years and years of interaction have yielded a rich collection of value optimal norms.
Our answer begins by noting that some buyers do read and understand. Professional buyers purchasing for businesses and organizations read to the extent that what they buy depends on contractual terms as well as on price and quality. In addition, those who read contracts can inform those who do not. Buyers can learn of terms that violate norms from consumer advocates and organizations, publications like Consumer Reports, and negative publicity arising from consumer complaints and litigation. Sellers themselves are another source of information. If United Airlines offers air travel on terms incompatible with relevant norms (excessive charges for baggage, for example), Southwest Airlines may call this to buyers’ attention in their advertisements. We will show that these informed buyers will buy from norm-compatible sellers. One crucial question is how many informed buyers there are. We address that question later.
We begin by noting that buyers prefer to buy from sellers offering terms compatible with value optimal norms. In ideal markets, perfect information entailed that buyers knew which sellers offered compatible terms. Since we were assuming perfect information, it made sense to build that knowledge into the definition of perfect information. But we don’t really need buyers to know perfectly which sellers offer norm-compatible terms. We just need buyers to find out eventually when sellers do not. Buyers will prefer to buy from the rest, the norm-compatible sellers.
Buyers’ detection of norm-compatible sellers will be imperfect, so “the rest” will also include some norm-incompatible sellers. The better detection is, the fewer norm-incompatible sellers will escape detection. We will assume very few. It is proper for us to do so since, as we noted earlier, our goal is just to show that the norm will arise if real markets sufficiently approximate perfect competition.
Preferring to buy from norm-compatible sellers is one thing; actually doing it is another. Everything else being equal, you might prefer to buy from Jones over Sam, but things aren’t equal. Jones is in New York, and Sam is in California where you are, so you buy from Sam. The zero transactions cost assumption eliminates all such difficulties in the ideal case, and thereby guarantees that buyers can translate their preference for norm-compatible sellers into reality. As part of our assumption of a sufficiently competitive market, we assume that transaction costs are low; they do not prevent most buyers from switching sellers. We note in passing that the assumption is plausible for a number of markets. The costs involved in switching from one Amazon Marketplace seller to another are not particularly great, for example. In addition, search and evaluation costs are relatively low—especially now that Internet searches offer very low-cost product identification and comparison and many shopping sites feature product reviews. We have reached the conclusion we reached in the ideal case: Informed buyers will switch to norm-compatible sellers—if such sellers exist.
Sellers
They will exist. To explain why, we begin by noting that sellers know that buyers prefer to buy from sellers offering norm-compatible terms. In the ideal case, we made this knowledge part of perfect information, but even in real markets, most sellers will know this. Norm-incompatible terms violate buyers’ values, and it is just common sense that people prefer to deal with those who do not violate their values (everything else being equal). Most sellers will know that. We also built it into the ideal case that sellers know that buyers know, for each term in a contract, whether it is norm compatible. In real markets, most sellers will know that some buyers know when contracts have norm-incompatible terms. They will realize the facts we noted above: Some buyers read and understand contracts, and consumer advocates alert buyers to adverse contractual terms, as do sellers’ competitors. So sellers will realize that some buyers will detect normincompatible terms in sellers’ contracts and will prefer not to buy from those sellers. We assume that barriers to entry and exit are low enough that most sellers can alter their contracts (and, if necessary, their products and services) to offer terms compatible with all relevant value optimal norms. But will they?
It seems the “real markets” argument is in trouble. When we got to this point in the ideal markets case, we could conclude sellers would realize that every buyer would detect sellers’ norm-incompatible terms and would prefer not to buy from those sellers. Since those sellers would be unable to sell at all, the profit-maximizing strategy was to offer norm-compatible terms. In real markets, we can get to almost the same result as long as there are enough buyers who detect whether contract terms violate norms that any gains sellers may get from offering norm-incompatible terms are more than offset by lost sales to those buyers. In real markets, however, only some buyers detect norm-incompatible terms, and there will not always be enough of these buyers.
Our strategy involves resolving this issue through redefinition. Our core assertion is that the norm will emerge within a sufficiently competitive market, and we include in the definition of such a market that there are a significant number of buyers who can identify terms that don't align with the norm. While this may seem like an evasion, it's not. We're proposing that if a real market approaches the conditions of a perfectly competitive market closely enough, the norm will develop. Our reasoning demonstrates that the definition of "close enough" must incorporate the presence of a substantial number of buyers capable of detecting norm-deviating terms, which offers actionable advice to those crafting policy. To ensure the emergence and persistence of the second-order norm, the one governing term compatibility, it's necessary to guarantee a significant population of buyers who can recognize norm inconsistencies.
At this point, in the ideal case, we concluded that profit-motive-driven sellers would include only norm-compatible terms since buyers will not otherwise buy from them. Can we similarly conclude that, when real markets sufficiently closely approximate the ideal, that most sellers will include (at least mostly) norm-compatible terms in their contracts? Not quite. If sellers could reliably discriminate between buyers who will and who will not detect a norm incompatibility, then sellers could offer norm-compatible terms to the incompatibility detectors and more seller-favorable, norm-incompatible terms to the rest. Mass-market sellers cannot reliably discriminate in this way, however. When you walk into a retail store or order an item over the phone or online, nothing reliably signals the seller whether or not you will detect norm-incompatible terms.* So, to the extent that real markets sufficiently closely approximate the ideal, most sellers’ contracts will contain (mostly) norm-compatible terms.
The result is not just a norm, but rather a coordination norm. The required regularity exists: Buyers demand contractual terms compatible with relevant value optimal norms. Buyers think they ought to conform, and they do so because, at least in part, norm-incompatible terms conflict with their values. The “ought” is, however, a conditional “ought,” as the definition of a coordination norm requires, unlike the ideal markets case.
The “ought” in that case was not conditional because sellers would meet even a single buyer’s demand. In real markets, however, mass-market sellers will not meet idiosyncratic demands; they respond only to demand that is sufficiently unified. So, as long as going without the service or product is not an acceptable option, a buyer thinks he or she ought to conform only as long as almost all others do. If almost all others demanded different terms, the buyer would conform to that demand.
* Unless you try to negotiate. If you detect a norm-incompatible term and object to it, you reveal yourself as an incompatibility detector. We are focusing on the no-negotiation cases.
How Contracting Can Go Wrong
The second-order, norm-compatibility norm emerges in any market that sufficiently closely approximates the ideals of perfect competition and contractual norm completeness. As long as the first-order norms are value optimal, the second-order norm ensures free and informed consent to standard-form contracts, even though we do not read them and would not fully understand them if we did. But what happens when markets fall far short of contractual norm completeness because there aren’t enough value optimal norms? The system breaks down, and we are left without any effective way to give our free and informed consent.
Contractual norm completeness can fail in two ways: Existing norms may be suboptimal, or certain situations may not be governed by relevant norms at all. We offered examples of both types of failures in earlier chapters. In the remainder of this chapter and the next chapter, we concentrate on what happens when there are no norms. We return to suboptimal norms at the end of the next chapter. Lack of relevant norms is characteristic of pay-with-data exchanges.
The Lack of Consent to pay-with-data Exchanges
The norms we need but do not have for pay-with-data exchanges are informational norms—specifically the norm that consumers demand that businesses process information only in role-appropriate ways that we discussed in Chapters 3 and 4. Recall that this is a coordination norm: a behavioral regularity that exists in part because people believe that, in order to realize a shared interest, they ought conditionally to conform to the regularity. No such norms exist for pay-with-data exchanges because we lack widely shared notions of role-appropriate information processing for such exchanges.
An analogy from the late 1800s shows why. Once Alexander Graham Bell’s patent on the telephone ran out, telephones started being fairly widely installed in private homes, but nobody knew just how to behave in using the phone. Should one say, “Hello?” or “Yes?” or even “Ahoy!” (as Bell suggested) when answering a phone? Who should be called? An 1897 article complained of people calling Chauncey Depew, then president of the New York Central & Hudson River Railroad, and shortly thereafter a US senator: Every time they see anything about him in the newspapers, and tell him what a “fine letter he wrote” or “what a lovely speech he made,” or ask if this or that report is true; and all this from people who, if they came to his office, would probably never say more than “Good morning.”19
But how could people have known just how to behave on the telephone in 1897? They lacked shared conceptions of role-appropriate behavior as telephone users. As people continued to use telephones, those conceptions and the associated coordination norms developed, but they did not exist at first. They arose over time out of repeated interactions.
We are in a similar situation with pay-with-data exchanges. The newly acquired power is the vastly increased ability to process information, and we lack relevant shared conceptions of role appropriateness. They will only evolve over time through patterns of social and commercial interaction. Instead of shared conceptions of appropriateness, we have the intense controversy that surrounds behavioral advertising. Several surveys (typically conducted by privacy advocates) report strong and widespread disapproval of behavioral advertising and the intense information processing that supports it. Other surveys (typically conducted by those who have a stake in behavioral advertising) present a more mixed picture. They still report significant consumer concern over behavioral advertising, but they also indicate a greater willingness to accept behavioral advertising under various conditions and constraints. Any adequate response to behavioral advertising must find a proper balance between protecting privacy and the economic gains of permitting the information processing; as James Rule notes, “We cannot hope to answer [complex balancing questions] until we have a way of ascribing weights to the things being balanced. And, that is exactly where the parties to privacy debates are most dramatically at odds.”20 We lack shared conceptions of role-appropriate information processing in many cases, in particular in pay-with-data exchanges.
When we take value optimal, first-order norms away from standard form contracting, we lose the background that ensures acceptable terms to which we give free and informed consent. Standard form contracting becomes mere notice and choice that businesses may exploit to impose whatever terms they want on us. The British retailer, Game Station, illustrated the potential to impose arbitrary terms by including the following clause in its terms-of-use contract on April 1, 2011: “By placing your immortal soul.”21 Customers could opt out of the license by clicking on a link included in the clause. Only a few did. The April Fool’s joke illustrates a genuine problem: Sellers do use contracts to impose on us information processing practices that significantly reduce our informational privacy.
The solution is to create the first-order, value optimal informational norms that we need. We will show how to do so in the next chapter.
Notes and References
1. The precise address is http://searchconsumerization.techtarget.com/news/2240160776/Apple-enhances-enterprise-mobile-device-security-withbiometrics (visited August 6, 2012). We generated the list using the Ghostery
add-on for the Chrome browser. See www.ghostery.com.↩
2. McKinsey Global Institute. 2011. Big data: The next frontier for innovation, competition, and productivity, June 2011, 1, http://www.mckinsey.com/Insights/MGI/Research/Technology_and_Innovation/Big_data_The_next_frontier_for_innovation↩
3. IBM. IBM what is big data? Bringing big data to the enterprise, accessed November 4, 2012, http://www-01.ibm.com/software/data/bigdata/↩
4. John Gantz and David Reinsel. 2010. The digital universe decade—Are you ready? IDC iView, sponsored by EMC, May 2010, http://www.emc.com/collateral/analyst-reports/idc-digital-universe-are-you-ready.pdf↩
5. McKinsey Global Institute. Big data: The next frontier for innovation, competition, and productivity, 2.↩
6. Lucas Mearian. 2011. Big data to drive a surveillance society. Computerworld, March 24, 2011, http://www.computerworld.com/s/article/9215033/Big data to_drive_a_surveillance_society↩
7. Federal Trade Commission. 2009. FTC staff report: Self-regulatory principles for online behavioral advertising, February 2009, 2, www.ftc.gov/os/2009/02/P085400behavadreport.pdf↩
8. Models may distinguish several more entities and functions. See, for example, IAB Data Usage and Control Taskforce. 2010. Data usage & control primer: Best practices & definitions, May 2010, www.iab.net/media/file/data-primerfinal.pdf↩
9. AdExchanger. 2010. eXelate announces Invite Media partnership; CEO Zohar offers insights on data marketplace. AdExchanger.com, January 26, 2010, http://www.adexchanger.com/data-exchanges/exelate-invite-media/↩
10. http://www.targusinfo.com/industries/finance/scoring/↩
11. http://www.targusinfo.com/about/data/ ↩
12. Garrett Sloane. 2010. amNY special report: New York City’s 10 hottest tec startups. amNewYork, January 25, 2010, http://www.amny.com/urbanite1.812039/amny-special-report-new-york-city-s-10-hottest-tech-startups-1.1724369 ↩
13. Center for Digital Democracy. 2010. In the matter of real-time targeting and auctioning, data profiling optimization, and economic loss to consumers and privacy, 2010, http://www.centerfordigitaldemocracy.org/sites/default/files/20100407-FTCfiling.pdf↩
14. Datran Media. Audience measurement. Aperture, accessed July 14, 2012, https://datranmedia.com/aperture/audience-measurement/index.php? showtype=for-publishers ↩
15. Sarah Downey. 2012. Our second web privacy census with UC Berkeley shows online tracking is at an all-time high [infographic] Abine, Online Privacy Blog, November 8, 2012, https://www.abine.com/blog/ (Reports a study that found that “26.3% of what your browser does when you load a website is respond to requests for your personal information. To put that in perspective, it means that only 73.3% of the time is your browser doing things you want it to do, like displaying videos, articles, and pictures. Google makes up 20.28% of all the tracking on the web, while Facebook is 18.84%. Less well-known trackers comprise the remaining 61%.” ↩
16. Peter Eckersley. 2010. How unique is your web browser? In Privacy enhancing technologies, Springer Lecture Notes in Computer Science, 2010, 1–18.↩
17. George John. 2009. Rocket fuel CEO John says ad exchanges more like a technology platform than media source. AdExchanger.com, August 24, 2009, http://www.adexchanger.com/ad-networks/rocket-fuel-ad-exchanges/ ↩
18. Privacy International. 2007. A race to the bottom: Privacy ranking of Internet service companies, September 6, 2007, http://www.privacyinternational.org/ article.shtml?cmd%5B347%5D=x-347-553961 ↩
19. Telephone cranks. 1897. Western Electrician XXI (July 17, 1897): 36–37.↩
20. James B. Rule. 2007. Privacy in Peril: How We Are Sacrificing a Fundamental Right in Exchange for Security and Convenience, 183. Oxford, UK: Oxford University Press.↩
21. 7,500 Online shoppers unknowingly sold their souls. 2010. Fox News, April 15, 2010, http://www.foxnews.com/tech/2010/04/15/online-shoppers-unknowingly-sold-souls/ ↩
About the Author
Ditsa Keren is a cybersecurity expert with a keen interest in technology and digital privacy.



Please, comment on how to improve this article. Your feedback matters!